Qualitative comparison against feedforward 3D editing baselines. Each row is one edit instruction: the leftmost panel is the Source 3D asset, followed by the 2D Condition reference, then each baseline’s result and our PartFlow output (highlighted). Click “Load 3D”, then drag any 3D viewer in a row — all 3D panels in that row rotate together.









Editing examples from the Pxform Dataset, grouped by edit type. Each card shows the Before 3D asset (left), the After result (right), and in the middle the 2D edited reference image with the edit instruction below it. Both 3D meshes are decoded from SLAT through the same pipeline. Click "Load 3D", then drag either viewer to rotate — the Before and After cameras stay in sync.



























We learn scalable feedforward 3D editing from semantic-part transformations. Pxform grounds every edit in semantic 3D parts, yielding over 100K consistent before/after editing pairs across seven edit types. Built on this supervision, PartFlow injects source-aware latent control into pretrained 3D generative priors, and combines mask-aware velocity preservation with render-space consistency supervision to jointly improve edit fidelity and source preservation — while requiring no 3D edit mask at inference.
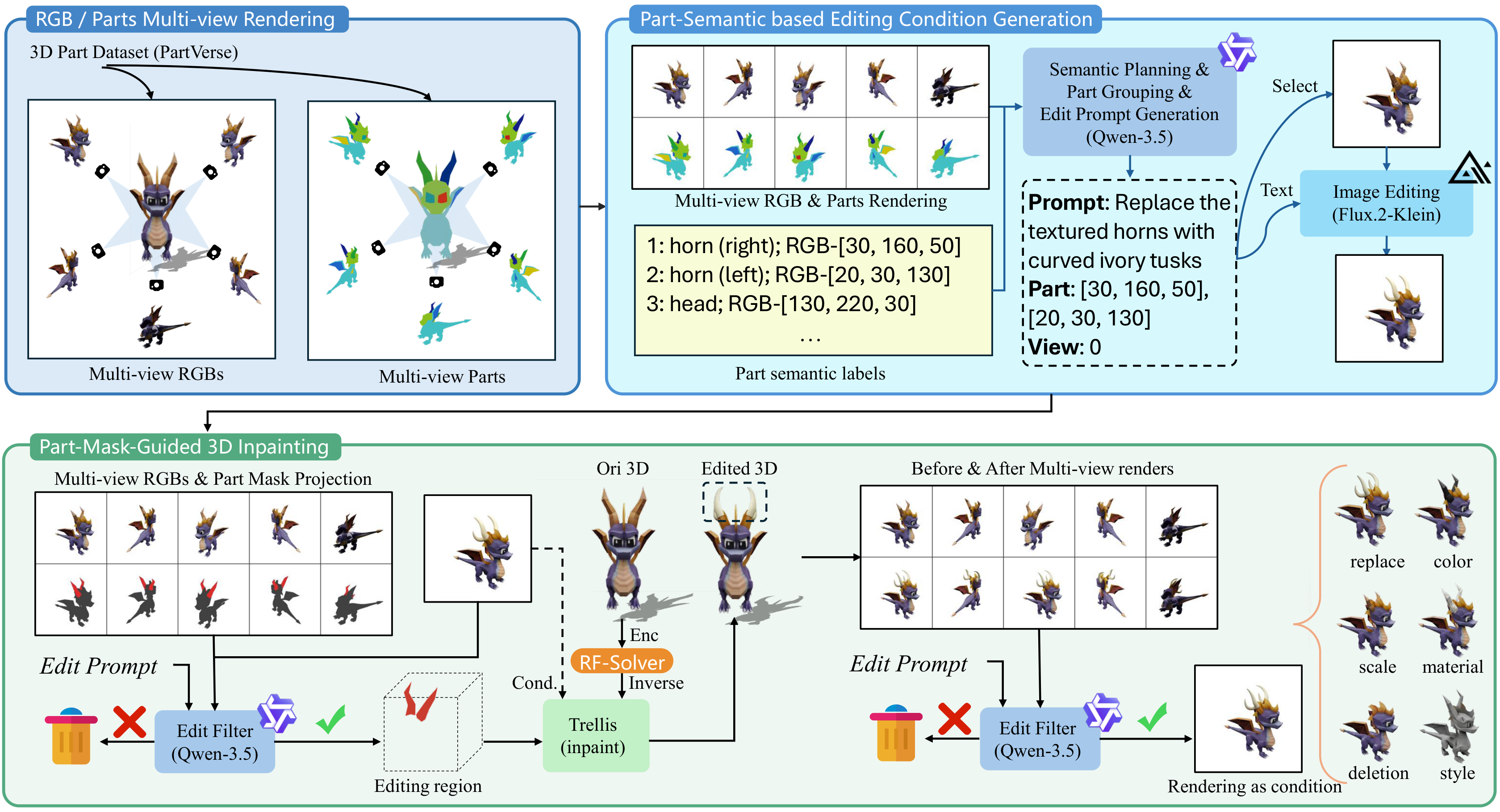
Fig. 1. The Pxform dataset construction pipeline — semantic-part-grounded 3D editing pairs.
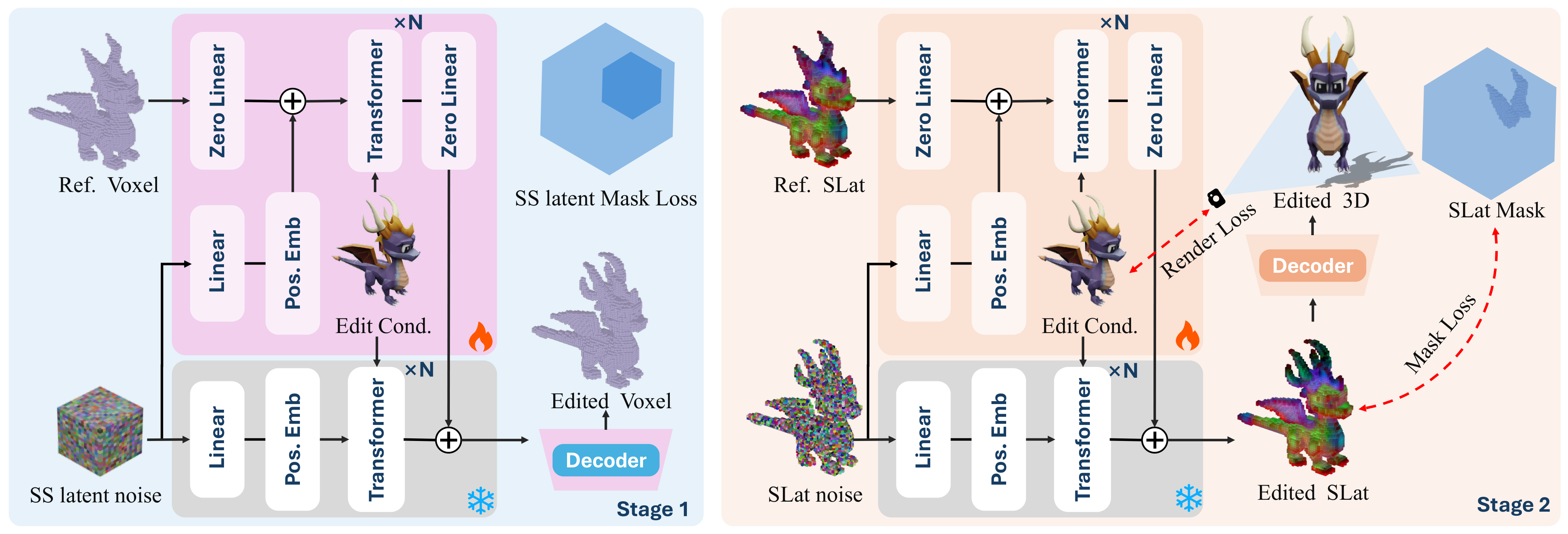
Fig. 2. Overview of the PartFlow feedforward 3D editing framework.
If you find PartFlow or the Pxform Dataset useful in your research, please consider citing our paper.
@article{weng2026feedforward,
title = {Feedforward 3D Editing Learns from Semantic-Part Transformation},
author = {Weng, Jiawei and Zhang, Saining and Diao, Zhenxin and Li, Peishuo and Zhang, Henghaofan and Chen, Junhao and Zhao, Hao},
journal = {arXiv preprint arXiv:2605.27351},
year = {2026}
}